Scala の Collection の使い分け
Scalaで開発をしていると様々な場面で Collection を使うことがあると思うが、Collection と言ってもScalaには多くの種類のクラスが存在する。
しかも、その種類はかなり多いうえに分類も大変だ。
まず、mutable なのか imutable。
さらに IndexedSec なのか LinearSec なのかでまったく用途や使い方が違う。
私自身もそうだが、Java から来た人は覚えること多く結構戸惑ってしまうのではないだろうか。
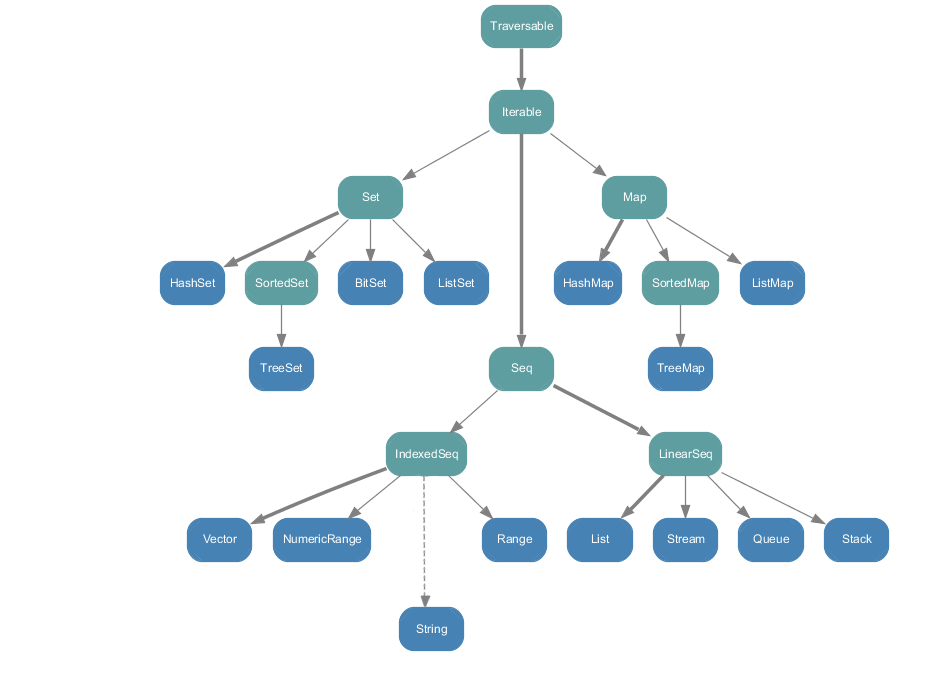
・scala.collection.immutable パッケージ内の全てのコレクション
・scala.collection.mutable パッケージ内の全てのコレクション
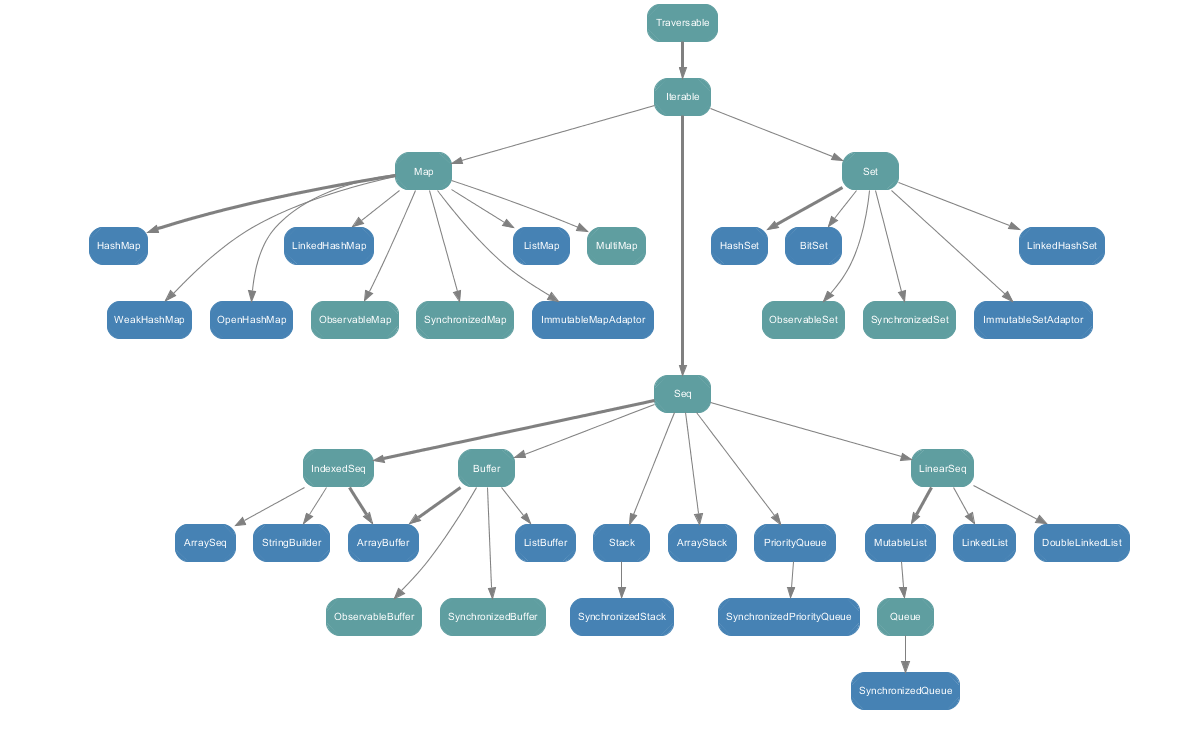
上記の各クラスのメソッドの種類や内容を紹介している記事やブログは多いのだが、どのクラスをどの場合に使えばいいのか、どういった用途にあっているかをまとめた内容が見当たらなかったので、今回どういった場合にどのクラスを使うべきかを簡単な例と一緒にまとめてみた。
種類が多いこともあり、今回は使うことが多い immutable な Seq をメインにまとめてみた。
Seq とは何か
Scala Documentaion には下記のように記述してある。
列 (Seq) トレイトは、長さ (length) があり、それぞれの要素に 0 から数えられた固定された添字 (index) がある Iterable の一種だ。
Seq トレイトには LinearSeq と IndexedSeq という二つの子トレイトがある。
これらは新しい演算を定義しないが、それぞれ異なった性能特性をもつ。
線形列 (linear sequence) は効率的な head と tail 演算を持ち、一方添字付き列 (indexed sequence) は効率的なapply、length、および (可変の場合) update 演算を持つ。
つまりは Seq というトレイトはリストや配列みたいなもので、2種類の子トレイトがあり、それぞれ次のような特徴がある。
■ LineardexSeq
先頭項目、末尾項目の追加、削除が高速だが、ランダムアクセスが遅いので先頭から順番に任意の処理していくのに向いている。
- head/tailが速い
- Java でいう配列、LinkedList
では、続いてIndexSeq、LineardexSeq の継承されている各クラスの内容と使い道を見ていこう。
IndexSeq

・Vector
Scala 2.8 から導入された新しいコレクションクラス。
Vectorクラスのコメントにもあるように、ランダムアクセスと更新が得意なので
基本的にはこれをデフォルトで使って良いそうだ。
Because vectors strikea good balance between fast random selections and fast random functional updates, they are currently the default implementation of immutable indexed sequences.
JavaでいうところのArrayListみたいなものだ。
実際にIndexedSecのデフォルトはVectorを生成するようになっている。
scala> IndexedSeq(1,2,3) res1: IndexedSeq[Int] = Vector(1, 2, 3)
・Range
等間隔で並べられたソート済みの整数シーケンス。
ちなみにRange以外で範囲が欲しい場合に、次のようにrangeメソッドを使うことも可能だが
scala> Vector.range(1,5) res1: scala.collection.immutable.Vector[Int] = Vector(1, 2, 3, 4)
範囲を使う場合に限ってはRangeが一番インスタンス生成が早いらしい。
Scala Seqメモ(Hishidama's Scala Seq Memo)
scala> Range(1 , 5) res27: scala.collection.immutable.Range = Range(1, 2, 3, 4)
・NumericRange
Rangeの汎用版。
Rangeの場合はIntしか扱えないが、それ以外の Char,BigDecimal,Long などが扱える.
scala> 'a' to 'd' res1: scala.collection.immutable.NumericRange.Inclusive[Char] = NumericRange(a, b, c, d) scala> 1L to 5L res25: scala.collection.immutable.NumericRange.Inclusive[Long] = NumericRange(1, 2, 3, 4, 5)
以上、ここまで、簡単にまとめると
- Int型の範囲が欲しい場合はRangeを使用
- Int型以外の範囲が欲しい場合NumericRangeを使用
- head/tailの処理がメインでない、ランダムアクセス、更新処理(実際には新しいインスタンスを生成)を行うことが多い場合、というより範囲をつかわない場合以外は基本的にはVectorを使用
では、続いて、LinearSeq の方を見て行こう。
LinearSeq

・Stream
リストに似ているが、要素は遅延評価されるので、無限の長さをもつことができる。
それ以外は List と同じ性能特性をもつ。
使われるまで値を評価しないので最後は "?" となっている。
scala> val stream = 1 #:: 2 #:: 3 #:: Stream.empty stream: scala.collection.immutable.Stream[Int] = Stream(1, ?)
上記から(val stream = (1 to 100000000).toStream)といった非常に大きな要素数をもつリストでも tream.tail といった処理は一瞬で返ってくる。(mapやfilterも同様)
大きな要素数を持つリストを操作したいときに有効。
※ただし、stream.max, stream.size, stream.sum といった Transformer method(※1) でないものは
java.lang.OutOfMemoryError を引き起こすので注意したい。
・Stack
後入れ先出し(LIFO) の列。
機能的にリストとかぶるので使われることはあまりない。
Stack の push は List の :: と同じで、pop は List の tail と同じ。
scala> import scala.collection.immutable.Stack import scala.collection.immutable.Stack scala> val stack = Stack(1, 2, 3) stack: scala.collection.immutable.Stack[Int] = Stack(1, 2, 3)
・Queue
Stackと似ているが、Stackと違って先入れ先出し (FIFO: first in first out) の列
scala> import scala.collection.immutable.Queue import scala.collection.immutable.Queue scala> val queue = Queue(1, 2, 3) queue: scala.collection.immutable.Queue[Int] = Queue(1, 2, 3)
・List
This class is optimal for last-in-first-out (LIFO), stack-like access patterns. If you need another access
pattern, for example, random access or FIFO, consider using a collection more suited to this than `List`.
List.scala のコメントにもあるように LIFO や head/tail の処理がメインの場合に使うべし。
ランダムアクセスなどの処理を使う場合は List 以外を使うようにすること。
ちなみににSeqのデフォルトはListを生成することから List ではなく Seq を使うのが一般的のようだ。
qiita.com
scala> Seq(1,2,3) seq: Seq[Int] = List(1, 2, 3)
以上、LinearSeq についてここまで、簡単にまとめると
- Stack, Queue については 同じ機能を持つListがVectorがすでに存在することから、あまり意識する必要はない。
- コレクションの要素数が非常に大きい場合や遅延評価を行うリストを使いたい場合は、Streamを使うと良い。
- head/tail の処理がメインの場合は List を使うといいが、Seq をなるべく使うようにしよう。
まとめ
以上、各コレクションの内容や特徴を見てきたが、パフォーマンスや用途の観点、使いやすさから Collection を選択する場合、やはり Vector を使うのが一般的かつ無難のようだ。
下記の記事、ドキュメントも是非参考にして欲しい。
- Listの主な処理が線形なのに対して、Vectorは全て実質定数。
Collections - 性能特性 - Scala Documentation
- 実際にパフォーマンスを計測したものだが、やはり Vector の使用を進めている。
参考
Collections - はじめに - Scala Documentation
Scalaでリスト処理
When should I choose Vector in Scala? - Stack Overflow
Scalaコレクションメモ(Hishidama's Scala collection Memo)
Scala Cookbook: Recipes for Object-Oriented and Functional Programming: Alvin Alexander: 9781449339616: Amazon.com: Books
Amazon.co.jp: Scalaスケーラブルプログラミング第2版: Martin Odersky, Lex Spoon, Bill Venners, 羽生田 栄一, 水島 宏太, 長尾 高弘: 本
※1 Transformer method
Transformer method とは名前の通り与えられたコレクションを新しいコレクションに変換するコレクションメソッドのことを指す。
map, filter, reverse などは与えられたコレクションを新しいコレクションに変換するので Transformer method であるが、max, size, sum などは上記の定義に当てはまらないのでそうではない。